LangGraph란?
LangGraph는 LangChain을 기반으로 만든 멀티에이전트 및 워크플로우 자동화 프레임워크이다. 쉽게 말해 AI 모델 간의 협업을 가능하게 하는 시스템이다.
기존 LangChain이 체인(Chain) 기반으로 순차적인 AI 응답을 처리했다면, LangGraph는 그래프(Graph) 구조를 사용해 더 유연하고 동적인 AI 상호작용을 제공한다. 이를 통해 비순차적 흐름, 반복, 상태 관리 등이 가능해진다.
=> AI 응답에 흐름, AI간 소통, AI 상태 관리 등을 다룰 수 있게 해줌.
LangGraph의 핵심 개념
1️. 그래프(Graph)
그래프는 여러 개의 노드(Node, 정점)와 엣지(Edge, 간선)로 구성된 자료 구조이다.
- 노드(Node): 데이터를 담고 있는 점(정점)
- 엣지(Edge): 노드 간의 관계(연결선)
LangGraph에서는 각 노드가 특정 작업(예: AI 모델 실행, 데이터 처리 등)을 수행하고, 엣지를 통해 흐름을 결정한다.
예시: ChatGPT에 여러 개의 프롬프트를 던지고, 각각의 응답을 분석한 후 최적의 답변을 선택하는 시스템을 만듦
2️. 상태 머신(State Machine)
상태 머신은 시스템이 특정 상태(State)에서 동작하고, 특정 조건이 충족되면 다른 상태로 전환되는 모델이다.
LangGraph에서는 "현재 상태(Current State)"를 기준으로 노드 간의 이동을 결정한다.
예를 들어:
- 상태 A(질문 분석)에서 사용자의 입력을 처리하고,
- 특정 조건이 충족되면 상태 B(요약)로 이동하며,
- 마지막으로 상태 C(응답 생성)에서 최종 결과를 출력하는 구조를 가질 수 있다.
즉, LangGraph는 특정 상태(State)에 따라 AI 모델의 동작을 다르게 조정할 수 있는 기능을 제공한다.
3️. 노드(Node)
LangGraph에서 노드는 개별 작업을 수행하는 단위이다.
- 예를 들어 프롬프트 처리 노드, AI 모델 실행 노드, 응답 요약 노드 등을 만들 수 있다.
- 노드는 독립적으로 동작하지만, 엣지를 통해 서로 연결된다.
=> 쉽게 설명하면 노드 == 함수라고 생각하면 됨.
4️. 엣지(Edge)
엣지는 노드 간의 연결을 담당한다.
- 한 노드에서 다른 노드로 이동하는 길을 정의한다.
- 엣지에는 조건(조건부 엣지, Conditional Edge)를 설정할 수도 있다.
5️. 상태 엣지(State Edge)
상태 엣지는 특정 상태(State)에 따라 엣지를 다르게 설정하는 개념이다.
- 예를 들어, 사용자의 입력이 질문이면 generate_response로 이동하고,
- 입력이 명령이면 execute_command로 이동하는 방식이다.
Generate & Reflect
LangGraph에서 멀티에이전트 시스템을 만들 때 중요한 개념이 Generate와 Reflect이다.
1️. Generate
- Generate(생성)는 AI가 새로운 응답을 만들어내는 과정이다.
- 주어진 입력을 기반으로 새로운 텍스트를 생성하는 역할을 한다.
2️. Reflect
- Reflect(반영/피드백)는 AI의 응답을 분석하고 개선하는 과정입이다.
- AI가 생성한 응답을 다시 평가하고 수정할 수 있다.
즉, Generate가 새로운 내용을 만들고, Reflect가 그 내용을 검토하는 역할을 한다.
이 두 개념을 활용하면 AI 응답의 품질을 향상시킬 수 있다. => AI 간 티키타카 가능하게 함.
LangGraph 실행
LangGraph 설치
1. 가상 환경 생성
conda create --name langgraph_env python=3.11
conda activate langgraph_env
2. LangGraph 설치
pip install langgraph
pip install langchain langchain-openai
pip install langchain-community langchain-core
pip install load_dotenv -> env 파일 읽어오기 용
Test 1: LangGraph 설치 확인
from langgraph.graph import StateGraph
print("LangGraph successfully installed!")
# LangGraph successfully installed!
Test 2: GPT API 사용
(.env 파일 생성 후 OPENAI_API_KEY=your-api-key-here 작성)
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage
# .env 파일에서 환경 변수 로드
load_dotenv()
# GPT-4o-mini 설정
gpt4o_mini = ChatOpenAI(
model_name="gpt-4o-mini", # GPT-4o-mini
temperature=0.7,
max_tokens=150,
)
# GPT-4o 설정
gpt4o = ChatOpenAI(
model_name="gpt-4o", # GPT-4o
temperature=0.7,
max_tokens=300,
)
# GPT-4o-mini 사용
response_mini = gpt4o_mini.invoke([HumanMessage(content="안녕 너 소개해봐")])
print(response_mini.content)
# GPT-4o 사용
response_full = gpt4o.invoke([HumanMessage(content="안녕 너 소개해봐")])
print(response_full.content)
'''
안녕하세요! 저는 AI 언어 모델로, 다양한 주제에 대해 질문에 답하거나 정보를 제공하는 역할을 합니다. 대화, 글쓰기, 지식 공유 등 여러 가 지 분야에서 도움을 줄 수 있습니다. 궁금한 점이 있으면 언제든지 물어보세요!
안녕하세요! 저는 AI 언어 모델인 ChatGPT입니다. 여러분의 질문에 답변하고 다양한 주제에 대해 대화할 수 있도록 설계되었습니다. 궁금한 점 이나 도움이 필요한 부분이 있으면 언제든지 말씀해 주세요!
'''=> OpenAI api key 발급 필수, billing 설정해야할 수도 있음.
StateGraph란?
StateGraph는 LangGraph에서 상태 기반 AI 워크플로우를 구축할 때 사용하는 핵심 개념이다.
쉽게 말해, StateGraph는 "상태 기반 흐름을 정의하는 그래프"라고 생각하면 된다.
LangGraph는 그래프(Graph) 구조를 기반으로 동작하며, 각 노드(Node)가 특정 작업을 수행하고, 엣지(Edge)를 통해 상태(State)에 따라 흐름이 결정된다.
StateGraph는 이런 그래프 구조에서 상태를 관리하는 핵심 프레임워크이다.
설치
pip install grandalf -> graph 볼수 있게 해줌print(app.get_graph().draw_mermaid())
=> 출력된 결과를 https://mermaid.live 에 옮기면 그림으로 보여줌
app.get_graph().print_ascii()
=> 콘솔에 그래프 직접 출력가능
Test 1: 기본 StateGraph
from langgraph.graph import StateGraph, START, END
from typing import TypedDict
# 그래프의 상태를 정의하는 클래스
class MyState(TypedDict):
counter: int
# StateGraph 인스턴스 생성
graph = StateGraph(MyState)
# 카운터를 증가시키는 노드 함수 정의
def increment(state):
return {"counter": state["counter"] + 1}
# 'increment' 노드 추가
graph.add_node("increment", increment)
# START에서 'increment' 노드로 엣지 추가
graph.add_edge(START, "increment")
# 'increment' 노드에서 END로 엣지 추가
graph.add_edge("increment", END)
# 그래프 컴파일
app = graph.compile()
# 그래프 실행
result = app.invoke({"counter": 0})
print(result)
print(app.get_graph().draw_mermaid())
app.get_graph().print_ascii()
# "counter": 1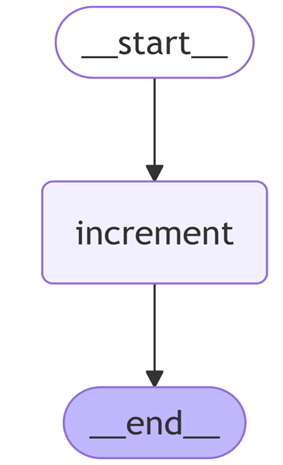
Test2: 조건 분기 StateGraph
from typing import Literal, Optional, TypedDict
from langgraph.graph import StateGraph, START, END
import re
# 날씨 데이터 (날씨 상태 + 온도)
weather_data = {
"New York": ("Sunny", "25°C"),
"London": ("Rainy", "15°C"),
"Tokyo": ("Cloudy", "20°C"),
"Paris": ("Partly cloudy", "22°C"),
}
# 상태 클래스
class QueryState(TypedDict):
query: str
location: Optional[str]
response: Optional[str]
# 질문을 분류하는 함수
def classify_query(state: QueryState):
query = state["query"].lower()
if "weather" in query and "in" in query:
return {"query_type": "weather"}
elif "temperature" in query and "in" in query:
return {"query_type": "temperature"}
else:
return {"query_type": "unknown"}
# 위치 추출 함수
def extract_location(query: str) -> Optional[str]:
words = query.split()
if "in" in words:
index = words.index("in")
if index + 1 < len(words):
location = words[index + 1]
if index + 2 < len(words) and words[index + 2][0].isupper():
location += " " + words[index + 2]
location = re.sub(r"[^\w\s]", "", location) # 문장부호 제거
return location
return None
# 날씨 상태 응답 생성
def get_weather_response(state: QueryState):
location = state["location"]
if location in weather_data:
weather, _ = weather_data[location] # 날씨 상태만 가져오기
return {"response": f"The weather in {location} is {weather}."}
return {"response": "Weather data not available."}
# 온도 응답 생성
def get_temperature_response(state: QueryState):
location = state["location"]
if location in weather_data:
_, temperature = weather_data[location] # 온도만 가져오기
return {"response": f"The current temperature in {location} is {temperature}."}
return {"response": "Temperature data not available."}
# 일반적인 질문에 대한 기본 응답
def handle_unknown_query(state: QueryState):
return {"response": "I'm not sure. Please ask about weather or temperature."}
# 상태 그래프 생성
workflow = StateGraph(QueryState)
# 노드 추가
workflow.add_node("classify_query", classify_query)
workflow.add_node("get_weather", get_weather_response)
workflow.add_node("get_temperature", get_temperature_response)
workflow.add_node("handle_unknown", handle_unknown_query)
# 시작 지점 설정
workflow.add_edge(START, "classify_query")
# 조건부 에지 추가
workflow.add_conditional_edges(
"classify_query",
lambda state: state["query_type"],
{
"weather": "get_weather",
"temperature": "get_temperature",
"unknown": "handle_unknown",
},
)
# 그래프 실행
executor = workflow.compile()
# 다양한 질문을 테스트
test_queries = [
"What is the weather like in New York?",
"What is the temperature in Tokyo?",
"Can you tell me the weather in Paris?",
"How hot is it in London?",
"Is it raining in Tokyo?",
"Tell me the temperature in Seoul.",
]
for query in test_queries:
result = executor.invoke(
{"query": query, "location": extract_location(query), "response": None}
)
print(f"Query: {query}")
print(f"Response: {result['response']}")
print("=" * 40)
'''
Query: What is the weather like in New York?
Response: The weather in New York is Sunny.
========================================
Query: What is the temperature in Tokyo?
Response: The current temperature in Tokyo is 20°C.
========================================
Query: Can you tell me the weather in Paris?
Response: The weather in Paris is Partly cloudy.
========================================
Query: How hot is it in London?
Response: I'm not sure. Please ask about weather or temperature.
========================================
Query: Is it raining in Tokyo?
Response: I'm not sure. Please ask about weather or temperature.
========================================
Query: Tell me the temperature in Seoul.
Response: Temperature data not available.
========================================
'''
Test 3: MessageGraph
(.env 파일 생성 후
OPENAI_API_KEY="<your-api-key>"
LANGSMITH_TRACING=true
LANGSMITH_ENDPOINT="https://api.smith.langchain.com"
LANGSMITH_API_KEY="<your-api-key>"
LANGSMITH_PROJECT="<ProjectName>" 작성)
from typing import List, Sequence
from dotenv import load_dotenv
from langchain_core.messages import BaseMessage, HumanMessage
from langgraph.graph import END, MessageGraph
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
load_dotenv()
# Reflection Prompt (일반적인 조언을 금지하고 반드시 구체적인 피드백을 제공하도록 수정)
reflection_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""당신은 커리어 전문가입니다. 이전 단계에서 생성된 자기소개 문장을 검토하고, 자기소개 개선을 위한 구체적인 피드백만 제공합니다.
반드시 지켜야 할 규칙:
1. 자기소개 문장을 제외한 일반적인 조언(예: '자기소개 문장을 지속적으로 발전시키세요')은 절대 생성하지 마세요.
2. 기존 문장의 강점을 1~2개 짚어주세요.
3. 반드시 개선이 필요한 요소를 명확히 제시하세요.
4. 수정 방향을 구체적으로 설명하세요 (예: "React 경험을 강조하는 것이 좋습니다.").
5. 직접 수정된 문장을 제공하지 마세요.
6. 반드시 새로운 개선점을 제공하세요. 같은 피드백을 반복하지 마세요.
금지 예제:
- '자기소개 문장을 지속적으로 발전시키세요.'
- '더 이상 수정할 필요가 없습니다.'
- '충분히 좋습니다.'
올바른 예제:
- '기술 스택을 구체적으로 나열하는 것이 좋습니다. (예: Python, FastAPI)'
- '백엔드 경험을 강조할 때, 주요 프로젝트와 기여도를 포함하세요.'
- '최근 AI 관련 프로젝트가 있다면 이를 추가하세요.'
반드시 자기소개 문장과 관련된 피드백만 제공하세요.""",
),
MessagesPlaceholder(variable_name="messages"),
]
)
# Generation Prompt (Reflection 피드백을 반드시 반영하도록 설정)
generation_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""당신은 프로페셔널한 커리어 코치입니다. 사용자의 자기소개 문장을 개선해야 합니다.
반드시 지켜야 할 규칙:
1. Reflection에서 제공한 피드백을 반드시 반영하세요.
2. 기존 문장을 반복하지 말고, 피드백을 반영하여 발전된 버전을 생성하세요.
3. Reflection이 제공한 '강점'을 유지하면서 '개선점'을 보완하세요.
4. 자기소개 문장 이외의 일반적인 응답(예: '도움이 필요하면 언제든지 말씀하세요' 같은 문구)은 생성하지 마세요.
답변이 Reflection에서 제공한 피드백을 기반으로 점점 더 개선되도록 하세요.""",
),
MessagesPlaceholder(variable_name="messages"),
]
)
llm = ChatOpenAI()
generate_chain = generation_prompt | llm
reflect_chain = reflection_prompt | llm
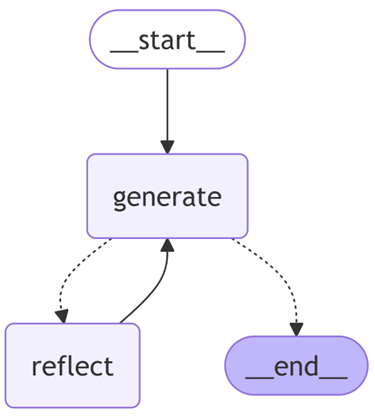
REFLECT = "reflect"
GENERATE = "generate"
MAX_ITERATIONS = 6 # 반복 횟수 제한
def generation_node(state: Sequence[BaseMessage]):
return generate_chain.invoke({"messages": state})
def reflection_node(messages: Sequence[BaseMessage]) -> List[BaseMessage]:
return [HumanMessage(content=reflect_chain.invoke({"messages": messages}).content)]
builder = MessageGraph()
builder.add_node(GENERATE, generation_node)
builder.add_node(REFLECT, reflection_node)
builder.set_entry_point(GENERATE)
def should_continue(state: List[BaseMessage]):
last_message = state[-1].content.lower()
if "자기소개 문장을 지속적으로 발전시키세요" in last_message:
print("\nReflection이 잘못된 피드백을 제공했습니다. 다시 요청합니다.")
return REFLECT
if len(state) > MAX_ITERATIONS:
print("\n최종 자기소개 문장:\n", state[-1].content)
return END
return REFLECT
builder.add_conditional_edges(GENERATE, should_continue)
builder.add_edge(REFLECT, GENERATE)
graph = builder.compile()
print(graph.get_graph().draw_mermaid())
print(graph.get_graph().print_ascii())
if __name__ == "__main__":
inputs = HumanMessage(content="저는 AI 개발 및 백엔드 경험이 있는 개발자입니다.")
response = graph.invoke(inputs)
'''
최종 자기소개 문장:
AI 개발 및 백엔드 경험을 보유한 전문가로서,
다양한 프로젝트에서 활약한 경력이 있습니다.
예를 들어, 최근에 음성 인식 기술을 활용한 스마트 홈 시스템을 개발하여
사용자들이 음성 명령으로 가전제품을 제어할 수 있는 서비스를 구현하는 데 성공했습니다.
또한, 백엔드 시스템을 구축하여 데이터 수집 및 분석을 효율적으로 처리하고
데이터베이스를 최적화하여 시스템의 성능을 크게 향상시켰습니다.
이러한 경험을 토대로 AI 및 백엔드 분야에서의 실전 능력을 바탕으로
문제를 해결하고 혁신적인 아이디어를 추구하는 데 주력하고 있습니다.
이를 통해 탁월한 결과물을 창출할 자신이 있습니다.
'''
=> Langsmith*를 이용해서 쉽게 결과 확인 가능 (https://www.langchain.com/langsmith)
=> 프롬프팅 중요함. (중간에 “완료하였습니다.”, “필요한 걸 말씀해주세요”, 등 원하는 결과가 아닌 값들로 반환될 시, 결과가 올바로 나오지 않을 수 있음. 해당 부분에 대한 방지작업 및 프롬프팅에 신경 써야함.)
=> 결국 LLM 간에 서로 피드백을 하다 보니 사용하는 토큰 수가 높아짐, 중간에 break하는 부분을 잘 설정해야 할 것으로 보임.
* LangSmith란?
LangSmith는 LangChain 기반의 AI 개발 및 디버깅 툴이다.
- AI 모델의 성능을 모니터링하고, 디버깅하며, 평가하는 기능을 제공한다.
- LangGraph와 함께 사용할 경우, AI의 실행 흐름을 시각적으로 확인하고, 성능을 최적화하는 데 도움이 된다.
LangSmith의 주요 기능
- 트레이싱(Tracing): AI 모델의 실행 과정을 추적
- 디버깅(Debugging): 예상과 다른 결과가 나오면 원인을 분석
- 성능 평가(Evaluation): AI 응답의 품질을 분석하고 최적화
- 실시간 데이터 모니터링: AI의 응답을 실시간으로 모니터링 가능
LangGraph + LangSmith 조합 예시
- LangGraph로 멀티 에이전트 워크플로우를 구축
- LangSmith로 AI 모델이 어떻게 동작하는지 모니터링 및 평가
- 필요하면 LangGraph에서 상태 전환을 수정하여 최적의 흐름을 구성
참고 자료:
LangGraph 가이드북 - 에이전트 RAG with 랭그래프 (https://wikidocs.net/book/16723)
'AI > LLM' 카테고리의 다른 글
| LangGraph를 활용한 데이터 전처리/요약 (0) | 2025.04.04 |
|---|---|
| Groq - LLM 무료 사용 사이트 (0) | 2025.04.03 |

