이제 완성된 crawling 코드를 이용하여 api를 만들예정이다.
폴더 구조는 다음과 같이 api, crawling 코드, schemas로 나누었다.
먼저 schemas에서는 api response데이터 타입을 검증해 주기 위해 pydantic을 사용하였다.
from pydantic import BaseModel
from typing import Optional
from datetime import date
class ActivityData(BaseModel):
ex_name: str
ex_link: str
ex_host: str
ex_image: str
ex_start: Optional[date]
ex_end: Optional[date] # 종료 날짜 없는 상황도 있음 (모집시 마감)
ex_flag: int # 대외활동 크롤링 위치 구분을 위한 플래그코드는 다음과 같다.
{'type': 'date_from_datetime_parsing', 'loc': ('response', 52, 'ex_end'), 'msg': 'Input should be a valid date or datetime, invalid date separator, expected `-`', 'input': '2024.11.15', 'ctx': {'error': 'invalid date separator, expected `-`'}}
해당 에러가 나타났다.
해당 에러는 date 타입으로 변경시에 .을 구분자로 썼을때(ex 2024.11.12), date로 변경 못해줘서 에러나 나는 것이다. 따라서 .을 -로 바꾸어 입력해주어야한다.
따라서 크롤링 코드에 . -> - 로 바꿔주는 코드를 추가해준다.
datetime.strptime(바꿀 데이터, "%Y.%m.%d").date()해당 코드를 통해 변경하면 된다!
그 후 api 코드에서 미리 만들어둔 크롤링 함수를 import해서 실행시키고 결과 값을 리턴해주면 된다!
from fastapi import APIRouter
from crawling.crawler import main as crawling_main
from schemas.crawling import ActivityData
from typing import List
router = APIRouter()
@router.get("/crawl", response_model=List[ActivityData])
async def get_activities():
activities = crawling_main()
return activities
그 후 main에서 해당 라우터를 호출하고, uvicorn main:app --reload 를 실행시켜주면 된다.
그 후 서버url/docs에 들어가 Swagger UI를 이용하여 api를 테스트 해준다.
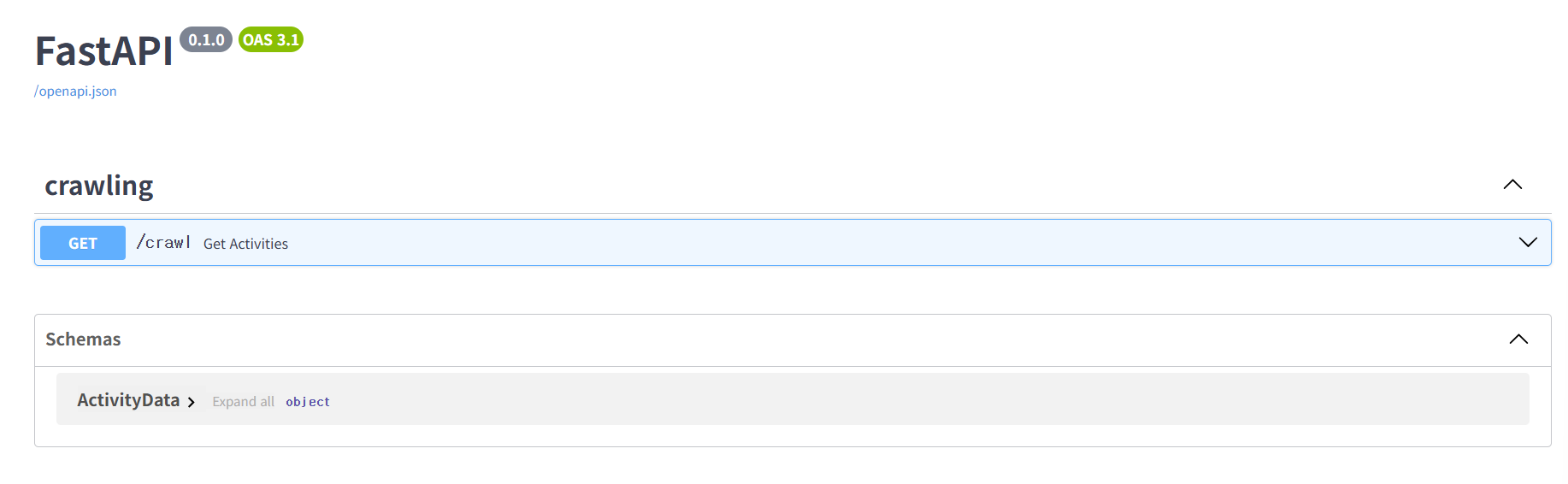
테스트 하면
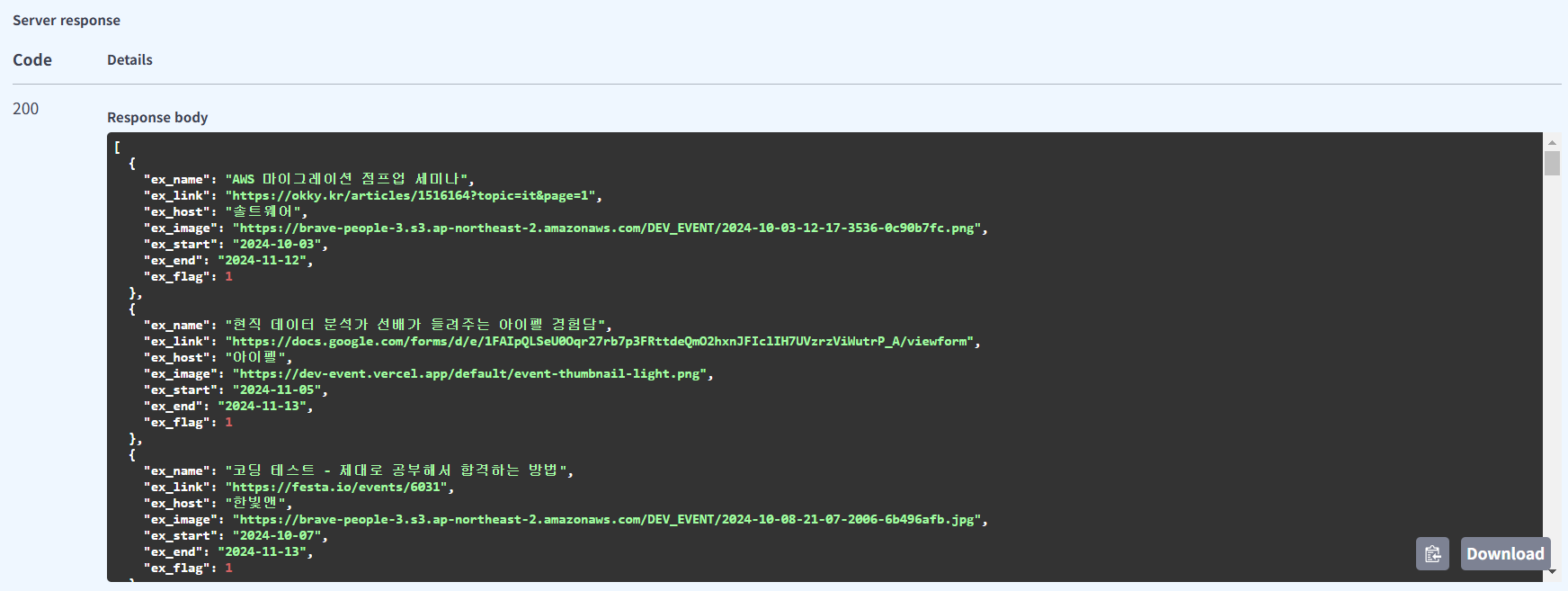
다음과 같이 결과가 잘 나오는 것을 확인할 수 있다.
이제 크롤링 서버 구현이 완료되어서 다음은 기본 백엔드 서버를 구현해보고자 한다.
모든 코드는
https://github.com/software-gathering/gather-be2
GitHub - software-gathering/gather-be2
Contribute to software-gathering/gather-be2 development by creating an account on GitHub.
github.com
여기서 확인 가능하다.
'Project > Gathering' 카테고리의 다른 글
| Gathering 기획 3 (1) | 2024.11.21 |
|---|---|
| Gathering 기획 2 (0) | 2024.11.16 |
| Crawling 구현 2 (0) | 2024.11.11 |
| Crawling 구현 1 (1) | 2024.11.08 |
| Gathering 기획 (0) | 2024.11.07 |



